ONES榮膺艾瑞報告典型廠商案例,引領企業級SaaS軟件開發新趨勢
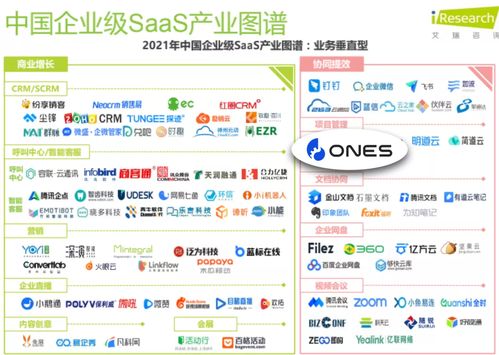
國內權威第三方研究機構艾瑞咨詢正式發布了《2021年中國企業級SaaS行業研究報告》。報告深入剖析了行業發展的宏觀背景、市場格局、細分賽道動態及未來趨勢。在備受關注的軟件開發與項目管理領域,國內領先的研發管理平臺ONES憑借其卓越的產品能力、成熟的企業服務實踐以及顯著的客戶價值,成功入選該報告的“典型廠商案例”,成為行業標桿。
報告指出,隨著數字化轉型浪潮的深入,企業對高效、協同、敏捷的軟件開發與項目管理工具需求日益迫切。傳統開發模式下的工具分散、流程割裂、數據孤島等問題,已成為制約企業研發效能提升與產品創新速度的關鍵瓶頸。企業級SaaS模式的研發管理工具,以其開箱即用、快速部署、持續迭代和高效協同的優勢,正成為眾多科技驅動型企業的共同選擇。
在此背景下,ONES作為一體化研發管理解決方案的提供者脫穎而出。其產品矩陣覆蓋了從產品規劃、項目跟蹤、測試管理到知識庫、效能度量等研發全生命周期,通過一個平臺打通需求、開發、測試、部署各環節,實現了研發過程的可視化、數據化和智能化管理。這不僅幫助團隊提升了協同效率,縮短了產品交付周期,更通過數據驅動為管理者的科學決策提供了有力支撐。
艾瑞報告將ONES列為典型案例,充分肯定了其在解決企業級客戶復雜研發管理挑戰方面的實踐成果。報告分析認為,ONES的成功在于其深刻理解了中國本土企業的研發管理痛點,并提供了貼合實際場景的靈活配置能力。無論是互聯網科技公司、金融科技企業,還是正在進行數字化轉型的傳統行業巨頭,都能基于ONES平臺構建適合自身特點的研發管理體系。這種“平臺化、可配置”的核心理念,相較于功能固化的單點工具,更能適應企業快速變化的業務需求和團隊規模擴張。
入選典型廠商案例,對ONES而言既是榮譽,也是責任。這標志著行業專家和市場對其產品價值與市場地位的認可。隨著中國軟件和信息技術服務產業的持續壯大,以及“軟件定義一切”的趨勢深化,企業級研發管理SaaS賽道潛力巨大。ONES等頭部廠商將繼續聚焦于技術創新與服務深化,通過更智能、更開放的產品生態,賦能更多企業構建核心競爭力,推動中國軟件開發行業整體效能與質量的躍升,在數字化浪潮中行穩致遠。
如若轉載,請注明出處:http://www.jiawang99.cn/product/26.html
更新時間:2026-06-19 22:08:52